We are basing our analysis on two datasets, a dataset of taxi use in New York and historical weather data. For both datasets, we initally planned to limit our analysis to 2019-02-01 00:00:00 – 2024-06-25 23:00:00, in the interest of trying to catch about a year of pre-Pandemic norms to help interpret Pandemic and post-Pandemic use of taxis. As noted in the next chapter, we had to abandon this scope. The inital upper bound reflects the extent of the weather data, and we initially planned on going back to January of 2019. However, no high-volume for-hire vehicle (FHVHV) data are available for January, so we bumped our limit to February, 2019.
The taxi data are provided by New York’s Taxi and Limousine Commission. They provide taxi data, in parquet format, going back to 2009. Since February of 2019, they have also included data on trips serviced by companies like Lyft and Uber, which are classified as “high-volume for-hire vehicle” trips. The data are updated monthly, with a two-month lag. Our focus is on yellow taxi and FHVHV trips, because our focus is on intra-Manhattan trips. Only yellow cabs can pick up passengers in most of Manhattan, so we are ignoring green cabs and regular for-hire vehicles (town cars and limousines). Yellow cab data have 19 columns, and FHVHV data have 24 columns. With our Python scripts, we consolidate the data to create aggregated hourly statistics on trip duration and trip distance. We found the transaction data (fare amount and tip amount) noisy with unreliable outliers. It also fell outside of our scope of analysis. We also included time-delta statistics comparing a point in time with the same point in time a week earlier. We did this because taxi data follow weekly patterns.
The historical weather data are provided by the Global Historical Climate Network hourly (GHCNh), which provides hourly weather data going back over two centuries for New York City. The data come in annual parquet files for download by station. Our station, KNYC0, is listed in the GHCNh as USW00094728, and it is the weather station in Central Park. The data come in over 200 columns to account for the variability that can occur in the terse METAR report for airplanes, which is also included under remarks. The government provides a codebook to describe the remaining data. As we are interested in what conditions determine a “nice” day for not using a taxi, we aimed to keep a wide array of data, including temperature, precipitation, wind, sky cover, humidity, and so on. We badly wanted to include snow data, but snow has been so infrequent during this window that we folded the snow numbers into the general precipitation numbers.
2.2 Missing value analysis
The taxi data are notoriously (as in, persistently) messy, registering trips outside the bounds of the time window and giving results that seem extremely unlikely, like large negative tips or negative trip durations. To counter these anomalies, we are limiting ourselves to trips between one minute and two hours long as well as trips of ten or fewer miles. Similarly, and, when consolidating monthly data to yearly data, we filter out all results from other years. In the aggregate, however, the outliers generally wash out, as we have a record of over 500 million yellow cab and Uber/Lyft rides. Nevertheless, there is one data point where no trips are recorded: 2:00am on March 10, 2019. However, there are data on both sides, so we will interpolate results for this time. Who knows what happened to the taxi system that affected both Uber and yellow taxis. Additionally, the tip amounts for Uber/Lyft are almost certainly incorrect, as over 75% of rides report no tip at all. As such, we will drop the tip and fare amounts from our data to account for this. We had suspected that a higher tip percentage might be related to a nice day, even though we assume taxi usage is lower, but the data are simply unreliable.
For weather, we have a large array of missing values, but the remarks column is missing only 36 entries, for a general station uptime of 99.93%. Many of the columns have many more missing values, but that is because the way the weather data work is by reporting a NaN for the absence of data. That said, we have a consecutive period of 24 hours’ worth of missing data across May 31, 2023 to June 1, 2023. This includes missing remarks, suggesting the station was down. In our imagination, a peregrine falcon ate the station.
The other 12 missing remarks are scattered across the dataset.
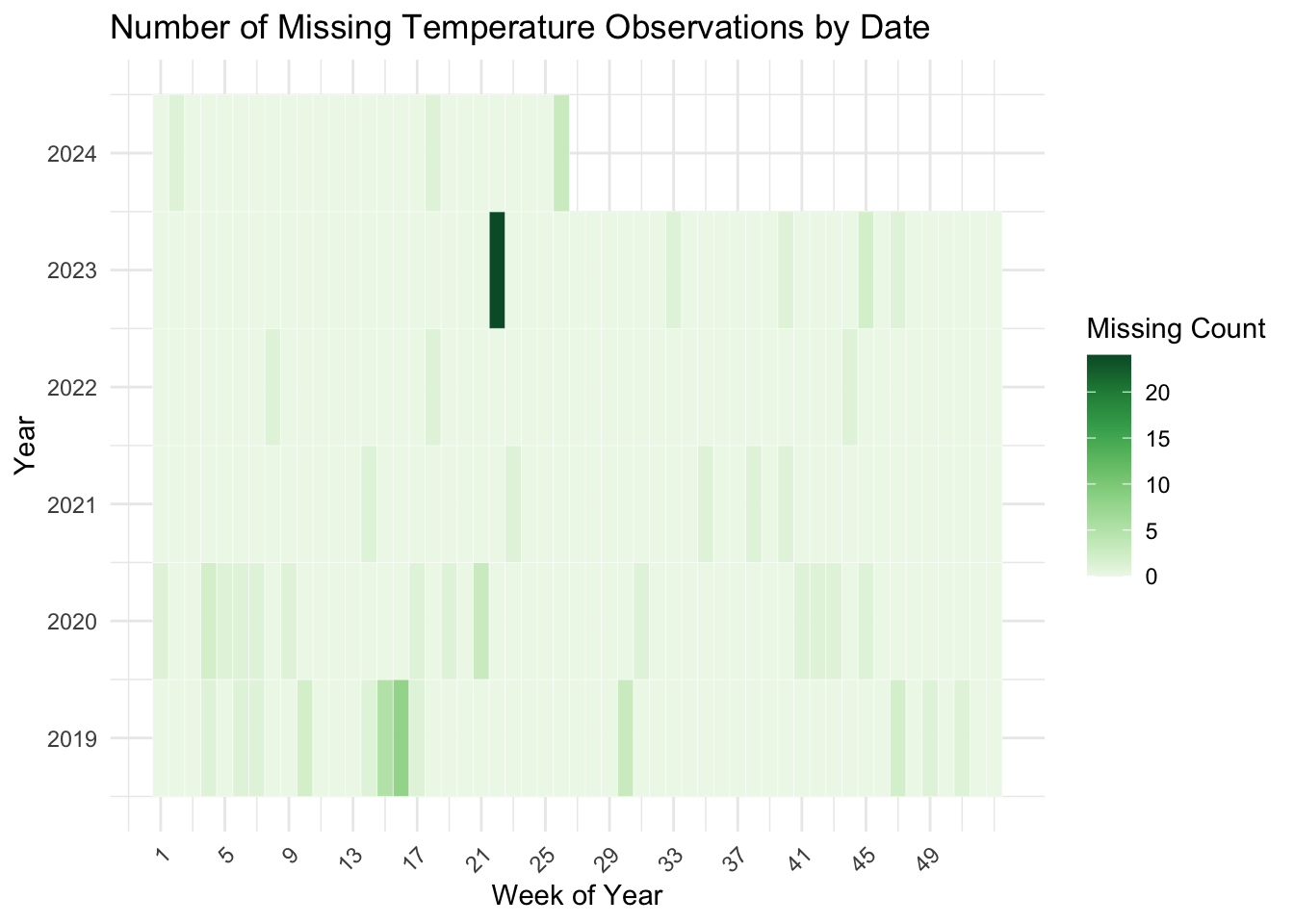
Because we have a total of 47,328 points in time in our dataset, it is hard to see any of the missing data in any plot that includes the entire stretch.
Code
df |>mutate(week_start=lubridate::floor_date(date, unit="week"),week = lubridate::week(date),year = lubridate::year(date)) |>group_by(year, week) |>summarize(n_missing=sum(is.na(temperature))) |>ggplot(aes(x = week, y = year, fill = n_missing)) +geom_tile(color ="white") +scale_fill_distiller(palette="Greens", name ="Missing Count", direction=1) +scale_x_continuous(breaks =seq(1, 52, by =4)) +scale_y_continuous(breaks =seq(2019, 2024, by=1))+labs(title ="Number of Missing Temperature Observations by Date",x ="Week of Year",y ="Year" ) +theme(axis.text.x =element_text(angle =45, hjust =1))
As we can see in this chart, the missing temperature data (our most important metric, we suspect) are mostly centered in that 24-hour period when the station recorded no data. The other gaps are scattered across the data, with a tilt toward the older data. This is why we are confident in simply interpolating data for the missing values. Another option is to derive the temperature from the point in time’s METAR report, but we suspect the METAR reports for the missing data may be unparseable, in general.
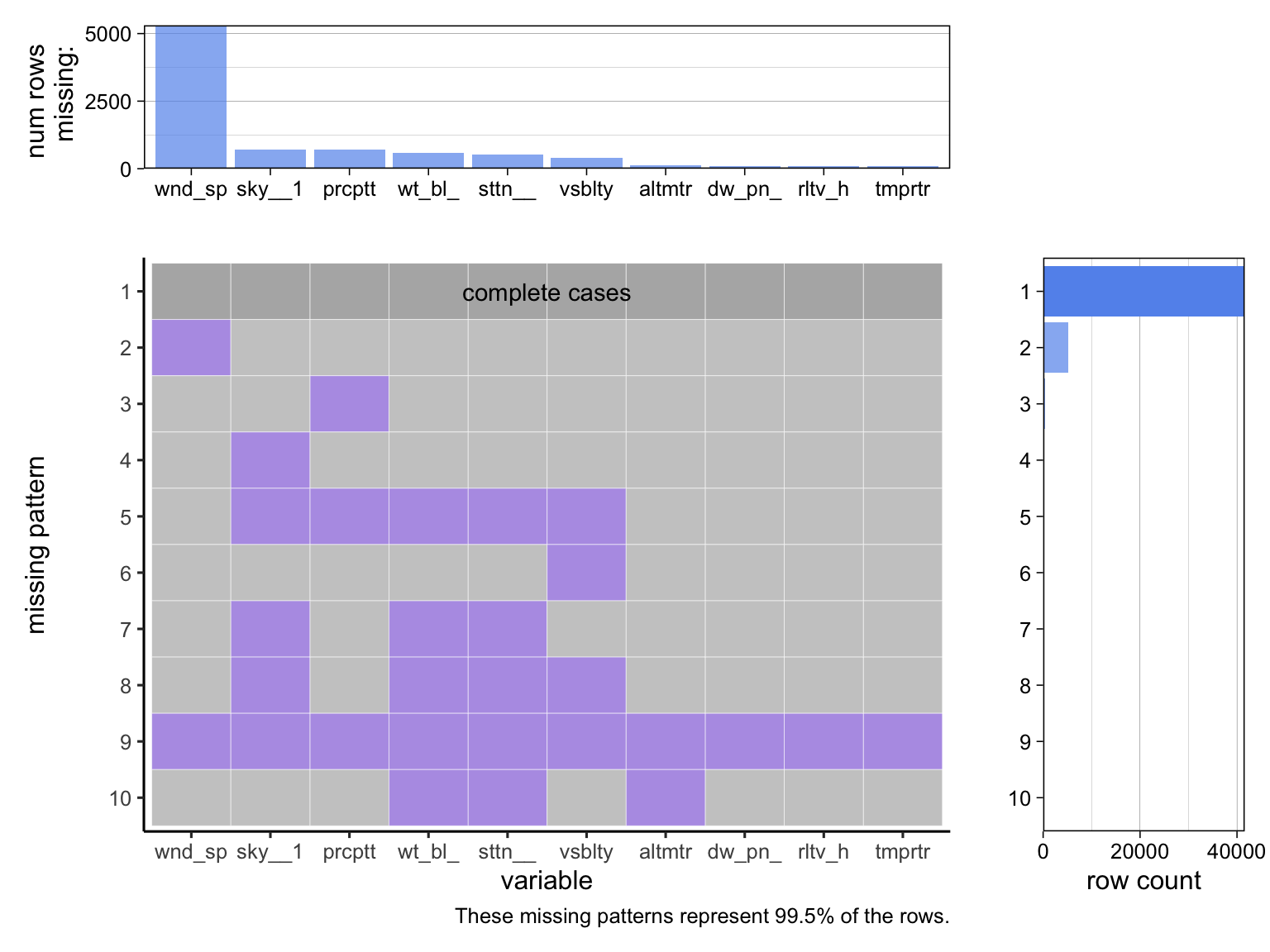
Our second chart shows the distribution of missing data, from which we can see how infrequently a wind speed is registered and that the rest of the missing data are scattered in small numbers around the dataset, with almost all of the data making up complete cases (minus the above extracted columns).
In the end, we shed so much data that the missing data become almost negligible. We combine several different descriptions of sky cover and precipitation to derive two new columns, cloud_cover and precipitation. We add in temperature, and that is about it. For the days when data are missing, we assume clear skies and no precipitation and interpolate the temperature from neighboring values.
For details on pre-processing the data, please see: